Nothing is more irredeemably irrelevant than bad science.
– John C. Polyani, quoted in Nobel Prize Winners 1987-1991
How Baer, Wolf, and Risley Were Wrong… but Wolf Was Right
There was a time, not so long ago, when most behavior analysts viewed survey research as the epitome of shady methodology. A survey study appearing in one of our fine journals would have evoked gasps of horror, in large part because, way back when, in the seminal description of applied behavior analysis (ABA), Baer, Wolf, and Risley (1968) told us that:
Applied research … asks how it is possible to get an individual to do something effectively. Thus it usually studies what subjects can be brought to do rather than what they can be brought to say; unless, of course, a verbal response is the behavior of interest. Accordingly a subject’s verbal description of his own non-verbal behavior usually would not be accepted as a measure of his actual behavior unless it were independently substantiated. Hence there is little applied value in the demonstration that an impotent man can be made to say that he no longer is impotent. The relevant question is not what he can say, but what he can do. [emphasis added]
Over the years I have heard more behavior analysts than I can count parrot the view that verbal report data, of any kind in any context, are inherently, fatally, tragically flawed. It was thus a very curious development in the history of behavior analysis when Montrose Wolf (1978) issued his seminal argument for collecting social validity data (“Social validity: The case for subjective measurement, or how applied behavior analysis is finding its heart”). Wolf knew he was poking the bear by endorsing what amounted to verbal-report measurement:
We have considered ourselves a natural science, concerned about the objective measurement of natural events such as arithmetic problems worked correctly, litter picked up, sexual responses occurring, and social skills learned. We have considered ourselves to be like the other natural sciences: like physics, chemistry, and biology, which concern themselves with the objective aspects of nature and profitably abandoned the subjective dimensions of natural events sometime in their primordial past….. We have considered ourselves to be distinctly purer and more objective than most of our sister social sciences. We have looked especially askance at our colleagues in sociology, anthropology, psychiatry, and humanistic psychology because they often mix into their sciences difficult-to-digest portions of subjective measurement.
Wolf (1978) pressed on anyway and made an eloquent case for using verbal reports to assess consumer satisfaction with behavioral interventions… although be braced himself for blowback.
You can imagine what I expected. I prepared for an onslaught of abuse, invective, and ridicule from our editors and our reading audience.

Improbably, despite the fact that social validity assessment traffics in the dark sorcery of verbal-report measurement, Wolf somehow persuaded us that it has a place in applied behavior analysis.
You now see social validity data in a sizable proportion of the field’s research reports. According to one review, that’s almost half of papers appearing in ABA journals. Verbal reports are in fact at the fore in most of those cases, although if you examine ABA research in the three or four decades following Wolf’s declaration, you’ll find that social validity assessment provides ancillary data in studies that continue to employ direct observation for the primary data.
Also, for decades this was a one-off, meaning that, outside of social validity assessment, ABA retained its general aversion to verbal-report measurement.
The Paw Paw of Procedures
Suddenly, however, things are different. Whatever ambivalence behavior analysts had about verbal-report measurement seems to have evaporated in recent years, and the ABA literature is sprouting survey studies like paw paw trees. Back in West Virginia where I grew up, the paw paw (see Postscript 1) is never a forest’s dominant tree, but you can scarcely stroll through the woods, anywhere, without encountering one. In the same fashion, if you keep up with today’s ABA literature, you’re now routinely seeing studies in which survey methods not only appear but provide the primary data.

This is not a transitory blip but rather a tidal change in the modus operandi of ABA research. I’d love to tell you that the change resulted from a discipline-wide conceptual re-evaluation of the role of verbal report-based measurement. Or from some uniquely behavior analytic breakthrough in survey methodology that resolved those traditional worries about verbal-report measurement. But the truth is less satisfying.
What did happen reflects a combination of exigency and necessity. Regarding exigency, look to the COVID-19 pandemic. In the wake of its mitigation circa 2019-2021, a whole bunch of investigators suddenly found themselves without in-person access to research participants. Survey-based studies, conducted remotely, offered one way to keep investigators on the tenure treadmill and students on track toward graduation. Shortly after COVID is when I first began receiving survey studies to review.
Regarding necessity, check out the graph below, showing the approximate point at which the growth in ABA practice shifted from merely frantic to purely insane. Around this time, it became obvious that a critical topic of study in ABA was the ABA profession itself. To build a proper profession, especially one encompassing almost 300,000 practitioners, you need information about a slew of professional (not scientific) issues. Surveys offered a way to find out who was doing and experiencing what out there in the field.
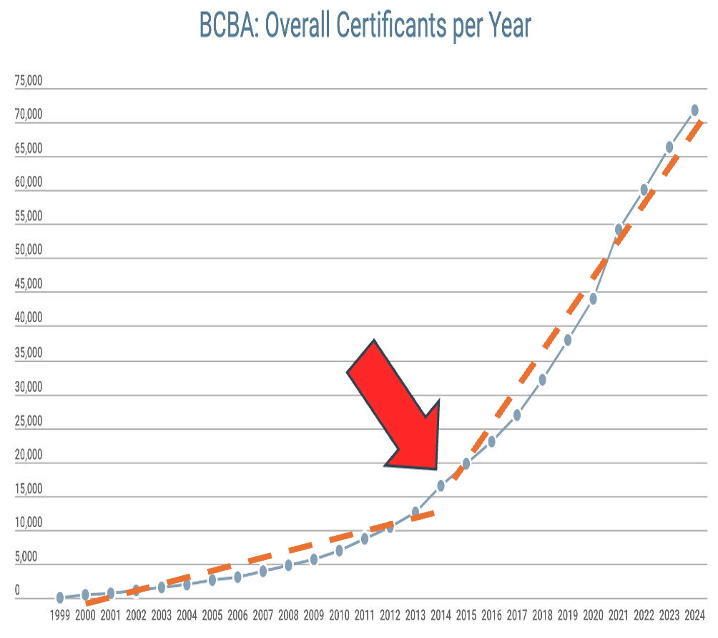
Dashed trend lines added.
The collective result of these two factors: Around the mid 2010s, we began to see an uptick an uptick in survey studies in behavior analysis journals. In a journal like Behavior Analysis in Practice (which, as the title implies, has a distinct practice focus), that means at least one survey study in almost every issue these days. Surveys are now part of the general landscape of ABA.
Dubious Methods
That’s all well and good, up to a point. I completely agree with Wolf that it can be useful to know what people say, especially about things that you’re unlikely to observe directly (see Postscript 2) — like what their experience may be of burnout or supervisory mistreatment or continuing education or a myriad other realities of the practice world that as an investigator you probably won’t observe directly.
And I’ve never understood the Baer et al. argument that verbal reports should be completely avoided because they might sometimes be inaccurate. All forms of measurement that are effective under some conditions are unreliable under others (that applies even to direct observation of behavior in the field and to automated recording of responses in the lab). Responsible research practice means employing tools under the conditions in which they’re effective. It’s no different with verbal-report measurement than for any other kind (for elaboration on this point, see the first portion of this chapter on self-report methods).
In point of fact, survey research is very good at what it’s for, given best practices that focus on conditions under which verbal reports are reasonably trustworthy (see the table below). Those best practices have been honed across more than a century of research.
There are a few behavior analysts who understand this, and if you notice somebody producing solid survey research, by all means extend a hearty verbal report of your satisfaction! Unfortunately, however, too many behavior analysts don’t employ best practices when conducting survey research. As mentioned, I’ve reviewed a lot of survey-based studies for behavior analysis journals. The large majority violated at least some of the commonly-accepted best practices that you can find in pretty much any undergraduate textbook on survey research.
| Some Survey Best Practices |
| Clear definition of the population of interest |
| Participant inclusion criteria based on the population of interest, and verification that all participants meet inclusion criteria |
| Empirical evidence of similarity (demographic + any other characteristics important to the research question) between participant sample and target population |
| Empirical evidence that survey items have acceptable psychometric reliability and validity |
| Empirical evidence that the participant N is sufficiently large to support the required data analyses (statistical power) |
| Sufficiently large N to support generalizations to the target population |
| Items worded to avoid well-known forms of survey-response bias |
| For forced-response (e.g., multiple-choice style) items, response options that respect best practices (e.g., number and types of alternatives) |
| For open-ended items, analysis guided by state of the art software for deriving response categories and objective procedures for coding responses into those categories |
| Empirical basis for assuming that, in lay terms, participants paid attention and gave good-faith answers to the questions (e.g., attention checks) |
| Reported effects verifies via data analysis techniques suitable to the structure of the data set (sorry, behavior analysts, this probably means statistical tools) |
To double-check my impressions, I’ve shown a few of those questionable papers to a colleague who specializes in survey design and teaches an undergraduate course in psychological measurement. His response: “Some of my undergraduates could do better.”
Thus, many ABA investigators doing survey research are unwittingly committing what the late-great Alan Baron called “mistakes of undergraduate proportions,” by conducting studies with easily-avoidable flaws. Skeptical? Check for yourself. Flip through ABA-focused journals, find some survey studies, and check them for violations of the best practices listed above. I guarantee you won’t struggle to identify examples.
There’s no benefit in calling out individual investigators, and I’m not picking on any one journal. At some level we must extend grace, because ours is a discipline in transition and there are bound to be hiccups as we evolve. Given our discipline’s historical preferences of methods, few ABA graduate programs teach survey methodology, so together we’re still learning how to gather and interpret verbal-report data in ways that are useful to ABA. In this regard we have few good role models. For instance, although Montrose Wolf blazed a trail toward verbal-report measurement, he established no functional methodological standards. Wolf’s classic article on social validity assessment shows exactly zero influence of well-established best practices of verbal report measurement. Wolf was right in wanting to know about social validity but, strangely for a behavior analyst, not much attuned to the methodological complexities of finding out (see Postscript 3). [That’s not just my appraisal; see also an insightful 1991 article by Ilene Schwartz and Don Baer that anticipates some of the present arguments.]
Look, everyone is good at some things and not at others. In that there’s nothing to criticize. What’s not okay is researchers practicing outside of their scope of competence by conducting studies for which they lack the necessary expertise. What’s even MORE not okay is our journals publishing those studies. I know saying this will earn me some enemies, but because of questionable methods, you can believe almost nothing you’ve seen in a survey study in a behavior analysis journal . This doesn’t mean the results are necessarily “wrong,” only that we can’t say, because the methods don’t justify trust in the results. And data like that don’t belong in archival journals.
An Easy Fix
What makes bad survey research so disappointing is that “mistakes of undergraduate proportions” are easily avoided. The world of survey research dwarfs behavior analysis scholarship, all types combined, and survey best practices are known by… well, just about everyone except behavior analysts.
Want to do a survey study? Great, go for it! But read a damn book first. There are a bunch of easy-to-digest textbooks, written for novices, that describe pretty much all of the basics that are required to bring behavior analysis surveys up to a minimum standard of quality.
- OR you can find informative chapters in more general books on psychological measurement (at times I’ve relied on Cohen and Swerdlik).
- OR you can download one of several how-to resources available for free online (Google it!)
- OR, if you’re completely averse to reading, try collaborating with someone who knows how to do surveys correctly. You’ll probably have to interact with someone who’s not a behavior analyst, but you’ll find a lot of curious, smart, competent, and reasonable people who have the right skills. Collaborating like this is a privilege, not a compromise!
Responsible investigator conduct is a start, but journal Editors, you need to enforce quality standards. That means better peer review. Unfortunately, few behavior analysts know what the standards should be, so finding competent reviewers is no doubt a challenge. But in science, folks, “This is hard” is never an excuse for doing shoddy work. Better for a journal to publish nothing at all than something that’s obviously flawed. A journal that cannot recruit survey-savvy reviewers should not publish survey research. [By the way, kudos to Behavior Analysis in Practice, which is already studying the problem described here and will be featuring a primer on minimum standards of survey construction, and adjusting editorial requirements accordingly.]
The Irony Is Palpable
Historically, we behavior analysts were dismissive of verbal-report measurement despite its lengthy track record of being pretty good at what it’s for. Then, when we finally saw value in survey data and began employing survey methods, we ignored the rules that make verbal-report measurement good at what it’s for. It’s time we turned things around by insisting that our researchers demonstrate at least an undergraduate level of competence in designing surveys and analyzing their results.
UPDATE (April 24, 2025)
My mentor, Mike Perone, reached out to remind me where I got my interest in verbal report methodology. Around the time I began graduate school, it was fashionable in human operant labs to interview participants to see what they understood about the contingencies with which they had interacted. This practice had roots tracing back to the 1950s, when cognitive researchers began claiming that what appears to be operant learning in humans isn’t real but rather an artifact of people’s conscious awareness of contingencies. In the 1980s people began also asking research participants to “think aloud” during experiments to gauge what they knew in the moment. This was spurred by the Ericsson and Simon (1984) book Protocol Analysis (see Hayes, 1986) and by early work investigating rule-governed behavior (e.g., Catania, et al., 1982)
Around that time, Mike wrote the following about the methods operant researchers were employing. Apologies, Mike — you influenced me far more than I realized while penning this post. Consider this my overdue verbal report to that effect!
. . . What is needed is a precise, quantitative, reliable, and valid instrument to collect and describe the reports. The eventual goal would be to develop measures of verbal behavior that are as refined as our measures of nonverbal behavior. At present, we may be too uncritical in accepting anecdotal verbal data.
There is an ironic twist to this last use of verbal reports. Interest in verbal reports has been defended on philosophical grounds by arguing that radical behaviorists recognize the importance of covert verbal events such as “self-instructions” and “self-rules” in human behavior, whereas only methodological behaviorists would restrict study to publicly observable events (e.g., see Bentall et al., 1985, pp. 178-179). Yet whatever their faults, methodological behaviorists have at least taken the business of collecting self-report data seriously (e.g., see Nunnally, 1978). They have developed a technology of test construction that ensures reliability, and they are acutely aware of the need for demonstrating the validity of their measures, even though behavior analysts might question their success at this. Concern with reliability and validity of verbal report measures is missing from the Journal of the Experimental Analysis of Behavior, although standards for nonverbal data are exacting. Perhaps we could learn something from the psychologists whose research has been based primarily on verbal reports. (Perone, 1988, pp. 74-75)
Postscript 1: Paw Paw Parable?

When I was a kid in West Virginia, only the most hardscrabble holler-dwellers ate paw paw fruits. My friends and I, products of free-range child rearing, used paw paws exclusively as projectiles in our perpetual Lord-of-the-Flies battles against one another and various imaginary enemies. It never occurred to us to put a paw paw in our mouths.
Nowadays, somehow, paw paws have become darlings of foodie culture and of the emerging hipster foraging movement. Lately, too, there’s been a resurrection of interest in indigenous beliefs about paw paws, which includes that they ward off evil witches (if true, count me in; my life is complicated enough without having to fend off evil witches).
In objective reality, the paw paws are neither garbage fruit nor magical superfood. They have lots of fiber and taste pretty good (Says one forager: “Their gooey, custardy texture isn’t for everyone, but holy cow do I love them.”). But paw paws are extremely messy to dig into and they spoil very quickly. Also, if you eat too many, the fiber… becomes a problem. And they contain the compound annonacin, which in chronic exposure is neurotoxic.
I sense some kind of parallel here with survey methods, but I’m not smart enough to explicate it clearly.
Postscript 2: On The Function of Survey Research
A proper understanding of survey research will address two general points: What kinds of questions are asked, and what kinds of answers are produced.
In the former case, some survey research focuses on (self-reports of) behaviors pretty much as the behavior analyst understands them. One familiar example is the Youth Risk Behavior Surveillance System, maintained by the US Centers for Disease Control and Prevention, which regularly surveys teens and adolescents about behaviors like cigarette smoking, illicit drug use, and unprotected sex. Another type of survey targets various kinds of constructs such as depression, anxiety, self-esteem, and so forth. Traditionally behavior analysts are not fans of such constructs, and I won’t litigate this except to say: Critics of constructs used outside of behavior analysis sometimes are conceptually inconsistent, apparently forgetting that a lot of things valued within behavior analysis are also constructs (e.g., social importance, consumer satisfaction, response rate, behavioral momentum, etc.). Let’s keep it simple and say that survey research in behavior analysts will most often ask questions about specific behaviors.
Survey research usually is engineered to provide actuarial answers to those questions. This is group-focused research, addressing group-level questions, such as how prevalent certain behaviors are in a given population. For instance, in the past decade or so we’ve seen surveys assessing the functional assessment tools used by practitioners; practices employed in supervising practitioners; stakeholders’ reactions to different job titles held by behavior analysts; the expressions of behavioral contrast encountered by practitioners in the field; publication practices of single-case researchers; and practitioner opinions about trauma-informed care. In all of these cases, the interest is in discovering what kinds of phenomena are most prevalent, rather than mapping functional behavioral relations in a single individual.
Because survey research usually is group research, the data must be analyzed using group-appropriate methods. Traditionally this includes both descriptive statistics (e.g., mean or median values, or distributions of values) and inferential statistics. Behavior analysts typically do okay with the former, but not so much with the latter, typically either eschewing inferential statistics or employing them incorrectly. Again, some grace is merited, because most behavior analysis training programs don’t teach much about inferential statistics. But when you don’t know something you need to know, the responsible thing is not to wing it but rather to self-teach. And, by the way, if you’re intolerant of Fisherian inferential statistics, as are many behavior analysts, all kinds of alternatives, carrying fewer conceptual liabilities, can be employed (e.g., randomization tests or Bayesian analyses).
Postscript 3: How Wolf was Wrong
Above, I gave Wolf a pretty hard time above for not emphasizing methodological rigor in social validity assessment. But a kinder appraisal would be that, given our discipline’s historical enmity toward “subjective” variables, Wolf needed to devote all of his energy to simply defending the view that social validity is an important thing to measure. No doubt a less skillful communicator would have been excoriated for even trying! Unsure of how his agenda would be received, Wolf in effect kicked the methodological details of social validity down the road. Toward the end of the “Finding its heart” article, he wrote:
Undoubtedly, there will be further important studies that point out to us the shortcomings of certain social validity measures, just as has been done for observer-dependent objective measures. But we can’t despair. After all, measurement has been our thing. In our field, we have developed so many ingenious measurement systems. There is no doubt that we could measure the disruptive classroom behavior of a school of fish, if need be. Surely, we will be able to develop measurement systems that will tell us better whether or not our clients are happy with our efforts and our effects. (Wolf, 1978, p. 213)
Wolf had faith that his normally methodologically-savvy ABA colleagues would create a uniquely behavior analytic set of best practices. It’s been close to 50 years since Wolf’s seminal article, and we’re nowhere close to justifying that faith. Turns out the road Wolf kicked his can down — one paved long ago by people outside of behavior analysis — remains the one less traveled by behavior analysts.
Slippery slope– rules of conduct (verbal behavior mostly) as behavior analysts, with many taught that the rule–based on science certainly–was/is absolute. A great blog that you might write would be to help us old timers and new timers see what is changing–what is morphing in the practice and content of behavior analysis. Could increase our innovation, exploration, translating our reality as behaving organisms into the work through a wider but still science-based provable lens. We might learn to see our various Truism as “good enough’ for right now without moving from science to supposition–or superstition. If you have done this already, just send me your article. Seems like your kind of thing– and I am always grateful. Darnell
Darnell, you are, as ever, insightful. The topic of this blog is indeed one exemplar of a large class of things that have some utility but have, in the dogma of our field, been labeled as evil, despite the fact that we offer no unique alternative for addressing the same problems. The fascinating thing to contemplate is how, having taken our original inspiration from the ultimate tinkerer (Skinner), we behavior analysts became so incredibly rule bound and thereby apparently incapable of embracing “good enough” or at least “good enough for now” solutions. I think the highly pragmatic practitioner movement is changing this (for instance, they’re doing a lot of surveys) and, for better and worse, introducing new variability into the culture of behavior analysis. If we truly believe in selection by consequences then this should be a good thing, right?