Guest Blog by: Jacob Sosine, RethinkFirst and Adrienne M. Jennings, Damean University

Jacob Sosine is a data scientist at RethinkFirst and a Board Certified Behavior Analyst. His work focuses on developing innovative tools and technologies that empower behavior analysts to better understand human behavior. Jacob is committed to creating solutions that are effective and accessible to professionals in behavior analysis by bridging the gap between technology and practical applications. His research interests are at the intersection of behavior analysis, technology, and machine learning/artificial intelligence. Jacob is also the creator of behaviorchain.ai, a tool for researchers and practitioners to better understand the extensive research literature within behavior analysis.

Dr. Adrienne Jennings is an Assistant Professor at Daemen University and a doctoral-level Board Certified Behavior Analyst. She has over 10 years of experience in clinical settings working with individuals with developmental disabilities and their families, in homes, in schools, and community organizations. She serves as the Research Competition Coordinator for the Verbal Behavior Special Interest Group and on the editorial boards of The Analysis of Verbal Behavior and Single Case in the Social Sciences. Her research interests related to verbal behavior include prerequisite skills for intraverbals and the role of verbal behavior in emergent behavior. Adrienne is also interested in artificial intelligence and incorporating data science in behavior analytic research. Additionally, her most recent project relates to the dissemination and cultural adaptations of behavioral services.
Data Collection at Intake
When ABA practitioners provide services to learners with autism and related disabilities, there are a variety of assessments that can be administered to help evaluate a learner’s verbal behavior (how they use language) during the initial intake appointments. Typically, the assessments include some measure of the learner’s vocal and nonvocal behaviors. For example, we track non-vocal verbal behaviors, such as pointing and gesturing, as well as vocal verbal behaviors such as echoics (repeating sounds), tacts (labeling), mands (making requests), and intraverbals (exchanges with a communicative partner or listener). We also measure instances of eye contact, as both initiations and responses. There are several assessment tools on the market that help us to quantify verbal behavior repertoires including the Verbal Behavior Milestones and Placement Program (VB MAPP; Sundberg, 2008), the Expressive Vocabulary Test (EVT; Williams, 2019), and the Peabody Picture Vocabulary Test (PPVT; Dunn, 2019), to name a few (see Lee et al., 2015 as an example of how the EVT and PPVT can support research findings). These assessment tools are useful for clinicians to measure a learner’s verbal behavior repertoire at the time of administration. Skill deficits are identified with those data, and treatment goals can be formulated.
When verbal behavior is in its early development, utterances can often be readily and neatly categorized. For example, we can use Skinner’s (1957) functional analysis of verbal behavior to determine the type of verbal operant emitted by reviewing the antecedent (what happens before the behavior), the behavior of interest, and the consequence (what happens after the behavior). Let’s say thatwe teach a learner to answer a personal information question, such as, “What is your mom’s name?” Perhaps we use a textual (or written) prompt (which is systematically and subsequently faded) and praise, along with tokens or some other reinforcer to teach this response. We say the intraverbal is established once the prompts are no longer required and the verbal stimulus by itself, “what is your mom’s name?” evokes the mom’s name. Although this is a simple response other more complex responses can be taught in similar ways For example, when we ask, “what’s a blue fruit?” and the learner replies, “blueberry” we can attribute their utterance to both “blue” and “fruit.” In an example of recalling past events we might ask “What did you think of the opener at the concert last night?” Responding to this question involves multiple sources of stimulus control (Palmer, 2016). For example, who we are talking to, or the audience, is one source of stimulus control that will impact our response. If we are talking to a friend that loves the opener that played, we might soften our opinion to be more agreeable. Responding to this question also involves recall (Palmer, 1991). The speaker may engage in a series of covert intraverbals, “Who did we see play last night? – Khruangbin – And who opened for them? Oh right, John Carroll Kirby and Logan Hone.” Recalling the name of the opener and visually imagining their performance can serve to evoke our resposne. We can’t as easily trace each of the sources of stimulus control that led to the response. The sources of control for such intraverbals are not only covert (or private, not a behavior we can see), but they also do not neatly fit into our antecedent-behavior-consequence analysis.
As verbal behavior increases in complexity, or, in other words, as verbal behavior becomes multiply controlled (Michael et al., 2011), it becomes a little less straightforward to measure and quantify. Multiple control is a broad, umbrella term to describe the various sources of stimulus control – or how we can predict when a certain behavior will happen and when it won’t happen. What we say, how we say it, and when we say it, are all impacted by our history, the audience (who is listening to us?), things we want and don’t want (states of deprivation and satiation), and other environmental considerations such as where we are (e.g., work, home), what time of day it is (e.g., just waking up, after a meal), and what we’re doing (e.g., in a rush to get somewhere, working on a difficult task). How can we measure verbal behavior and all the relevant stimuli that produced it? How do we determine mastery of what Skinner (1957) called “magical mands” or a skill as broad as conversation skills? How do we measure the impact of our intervention as verbal behavior increases in complexity? Vector embeddings isa technology that behavior analysts can leverage to account for more complex verbal emissions.
Vector What?
But what are vector embeddings? Where do they originate? And how could they be helpful to behavior analysts? To explain this, we will first examine two relevant examples of data collection regarding verbal behavior.
Imagine you are collecting data on the emission of tacts (labels) for a young learner. Every time the individual emits a tact, you write down the word used and add one to the count under that word. This goes on for some time, and eventually, you have a list of tacts used that day, along with how many times those tacts occurred. You decide to return the next day with all the words written out, ready to record more tacts. As you collect data, the individual starts to emit new tacts that do not match precisely the words that you have written out, and due to the emerging repertoire of the learner, your datasheet quickly starts to become overwhelming. Locating previously emitted tacts becomes difficult, and your ability to collect on all the unique tacting targets plummets. One reasonable solution would be to collect data only on a few select tacts or collect data on the rate of tacts within a given session. Ultimately, you may miss some emissions of the specific verbal operant, but prioritization is essential, and you can always manipulate the rate at which reinforcers are provided to increase or decrease the rate of tacts more generally. The individual’s behavior and repertoire were well represented by the measurement.

Photo by cottonbro studio from Pexels: https://www.pexels.com/photo/girl-reading-english-alphabet-3662801/
Here’s a different example. Suppose you are a professor working on shaping the verbal behavior of a graduate student. One activity might be to have an individual view a clip or movie and describe the antecedents, behavior, and consequences for a specific target behavior that occur in the clip. This training procedure could result in a multiply controlled verbal response emitted by the student that is difficult to quantify and describe using traditional measurement techniques. You could measure the occurrence or nonoccurrence of the behavior (i.e., the presence or absence of the tact), or you could develop and use a rubric to categorize components of the individual’s response (e.g., “How was the student’s use of measurement”: 1) No quantifiable elements, 2) Few quantifiable elements, 3) Several quantifiable elements, 4) Consistently uses quantifiable terms). When using the former, you aggregate the information in a way that is not useful in shaping the individual’s verbal repertoire. When using the latter, you rely on representing the important topographies of behavior in a layer of abstraction to categorize the individual’s behavior into categories. This measurement adds time, effort, and complexity for the student and the professor. The quantifiable aspects of the topography of behavior rely on the professor’s objective measurement using the rubric. The measure’s reliability would depend on interobserver agreement. New data collectors would need to be trained on the system and the data collection measurements. This is a situation where vector embeddings could be used to systematically measure the progress of the student’s verbal behavior as feedback is provided and the behavior is shaped.
[.54241, .21352, .90804, .10344, .53455, .35566 ]
A vector is a mathematical object with both magnitude and direction. It is typically represented as an array of numbers like those displayed above. An embedding is the mapping of some object to a continuous vector space. Vector embeddings are the numerical representation of the mapping of an object to the vector space. Vector embeddings get their roots in natural language processing (NLP) and emerge from a similar problem space that behavior analysts have with capturing complex verbal behavior. The traditional methods in NLP were much less robust and relied on counts of words (e.g., counting individual tacts); they used a fixed vocabulary for text analytics (e.g., coming to the session with your tacting data sheet already written out), had a hard time accounting for new data (e.g., the learner emits new tacts that do not fit precisely on the datasheet), and had an overwhelming amount of data that was difficult to efficiently process (e.g., the ability of the therapist to process new information efficiently). This vector embedding solution addresses many of these limitations by attempting to account for the semantic relationships between words, not their frequencies. They represent data in a continuous space and allow for comparisons between data described in this way.
The core idea behind vector embedding representations of data is that data with similar meanings tend to appear in similar contexts. Vector embeddings excel in representing these semantic relationships efficiently. For example, words like “cat” or “dog” might often appear near words like “pet” or “cute.” Whereas words like “dolphin” or “whale” might occur near words like “ocean” or “sea.” The vector representation for “cat” and “dog” would end up more similar to each other than “dolphin” or “whale,” but both may be equally similar to a word like “mammal.” This efficient representation allows a model to represent the semantic relationships between words based on how those words are used without explicitly programming the existing relationship. These ideas can be used with words, sentences, or even more significant amounts of text.
The Utility of Vector Embeddings in Behavior Analysis
Now that we understand more about how vector embeddings work, let’s discuss how they could be helpful to behavior analysts. When using a vector embedding model, you may input some text and expect to receive an array of numbers as an output. In our following example, we use a model that is available through OpenAI called text-embedding-ada-2. The model, through its training process, has learned to represent text as an n-dimensional array that captures the semantic relationship between sentences of text. This model can then allow new users to input text that has never been seen by the model to get the n-dimensional output. That n-dimensional output could then be leveraged for many different tasks and analyses, as well as being a quantified account of a speaker’s verbal behavior. To illustrate, let’s revisit our earlier example of a professor shaping the behavior of a graduate student’s account of behavior. Suppose a professor has a terminal instance of an ‘expert’ account of the behavior they are observing.
Expert Rater Example
| At 10:30 AM during free play, Tommy approached his peer who was holding a red toy car. Tommy extended his hand and said, “Can I have that?” The peer responded, “No, I’m using it.” He clenched his fists. His right hand swung in an arc, making contact with the peer’s left upper arm. The peer emitted a loud “Ow!” The teacher, standing 10 feet away, turned towards the sound. She walked to the children, grasped Tommy’s shoulder lightly, and guided him to a chair in the corner of the room. |
The professor can process that account using a vector embedding model. Afterward, the professor is left with an n-dimensional array of the expert’s account of the incident they described. This could look like the following.
| [.54241, .21352, .90804, .10344, .53455, .35566 ] |
Each time a student emits behavior describing the incident, the description can be processed using the same vector embedding model used to embed the expert’s example. This would give the professor the following information (Note that the actual vector embedding used for calculations in this example was 1536 dimensions using OpenAI’s ada-2 embedding model). In the examples below, we will assume the student is taking successive approximations toward the terminal goal of accounting for behavior in specific, observable, and measurable terms. The behavior emitted by the professor to shape the student’s behavior is outside the scope of this example.
| Tommy felt frustrated when his classmate wouldn’t share the toy car during playtime. Overwhelmed by his emotions, he lashed out and hit the other child. The classmate started crying, which made the teacher notice. Disappointed in Tommy’s behavior, the teacher sent him to sit in the timeout corner to think about what he’d done. | [.14502, .12360, .31244, .68488, .23204, .543534 ] |
| When his peer refused to give him the toy car during free play, Tommy became upset. Agitated by the situation, he swung his arm and struck the other child. The classmate yelped in pain, attracting the teacher’s attention. The teacher, disapproving of the action, separated the children and had Tommy sit in the designated timeout area. | [.12360, .31244, .12360, .543534, .68488, .23204 ] |
| Tommy was playing in the block corner when he reached for a toy car his classmate was holding. The classmate pulled the car away and said “No.” He raised his hand and hit the classmate’s arm. The classmate vocalized loudly, causing the teacher to look over. The teacher immediately came to the block corner and directed Tommy to the timeout chair across the room. | [.68488, .12360, .68488, .23204, .31244, .543534 ] |
| Tommy approached his peer who was holding a red toy car. Tommy extended his hand and said, “Can I have that?” The peer responded, “No, I’m using it.” Tommy’s shoulders tensed, and he clenched his fists. His right hand swung in an arc, making contact with the peer’s left upper arm. The peer said “Ow!” The teacher, standing 10 feet away, turned towards the sound. She walked to the children and guided Tommy to a chair in the corner of the room. | [.23204, .12360, .23204, .543534, .68488, .31244 ] |
The professor can then calculate the cosine similarity between the expert’s emission, and the student’s emission. Cosine similarity is one of many metrics for measuring the similarity between two or more vectors. The metric is constrained to a range between 0 and 1. The closer the value is to 0 means that the two vectors are orthogonal or perpendicular to each other. When the value is closer to 1, it means the angle is smaller and the two objects are closer (i.e., more similar).
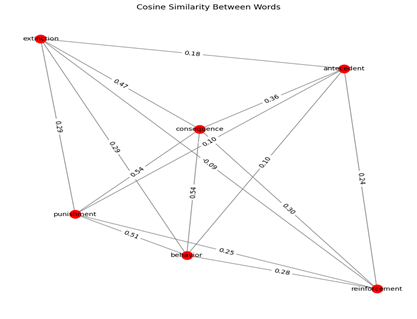
Figure 1. Displays a graphic of the cosine similarity between common behavior analytic words using the word embedding model glove.6B.100d. The nodes (i.e., behavior analytic words) are connected via edges (i.e., lines), and contain the cosine similarity of the two words within the path of the line. Image created by the author.
For this example, using a vector embedding model to account for the student’s behavior we then calculated the cosine similarity between the four emissions of the student and that of the expert, and we get the following values. Each of the emissions gets closer and closer to the expert’s description (i.e., the first emission from the student was not as similar to the last emission of the student as it relates to the expert’s description).
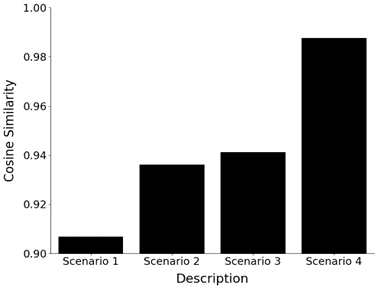
Figure 2. Displays the cosine similarity between the vector embeddings produced by the student’s successive emissions compared to the vector embedding produced by the expert’s emission. Image created by the author.
What Does the Future Hold?
As new technologies continue to emerge and the landscape of artificial intelligence continues to evolve, behavior analysts should explore these technologies and see which are helpful in the account of verbal behavior. We offered one example of one particular type of technology in this space. This specific technology could aid behavior analysts in accounting for more complex verbal behavior. Still, more experimentation and analysis are necessary to fully understand such technology’s bounds, limitations, and benefits for measuring verbal behavior. Furthermore, asking and answering questions like, “How was this vector embedding model trained?” or “What sort of tasks is this specific model good at?” or “What sort of biases exist within this model that I need to be aware of before using it?” are all fantastic starting points that may influence the utility of any one model for any specific task you are looking to accomplish.
We hope this blog post has inspired you to look beyond the traditional measurement techniques in behavior analysis and experiment, explore, and navigate the fantastic world of technologies outside our primary domain. Should this motivate you to explore this space, we encourage you to visit the resources below to add value to that endeavor and aid your journey!
Resources:
– https://www.youtube.com/watch?v=gQddtTdmG_8
– https://colab.research.google.com/drive/158OE-wAckQZuKUTMTMiJqa9uLAgOgJcs?usp=sharing
– https://platform.openai.com/docs/guides/embeddings/faq
– https://datastax.medium.com/how-to-implement-cosine-similarity-in-python-505e8ec1d823
– Jeffrey Pennington, Richard Socher, and Christopher D. Manning. 2014. GloVe: Global Vectors for Word Representation. [pdf] [bib]
– https://doi.org/10.17605/OSF.IO/B6XUH
References
Dunn, D. M. (2019). Peabody Picture Vocabulary Test (5th ed.). NCS Pearson.
Lee, G. P., Miguel, C. F., Darcey, E. K, & Jennings, A. M. (2015). A further evaluation of the effects of listener training on the emergence of speaker behavior and categorization in children with autism. Research in Autism Spectrum Disorders, 19, 72–81. https://doi.org/10.1016/j.rasd.2015.04.007
Michael, J., Palmer, D. C., & Sundberg, M. L. (2011). The multiple control of verbal behavior. The Analysis of Verbal Behavior, 27(1), 3–22. https://doi.org/10.1007/BF03393089
Palmer, D. C. (1991). A behavioral interpretation of memory. In L. J. Hayes & P. N. Chase (Eds.), Dialogues on verbal behavior (pp. 261-279). Reno, NV: Context Press.
Palmer, D. (2016). On intraverbal control and the definition of the intraverbal. The Analysis of Verbal Behavior, 32(2), 96–106. https://doi.org/10.1007/s40616-016-0061-7
Skinner, B. F. (1957). Verbal behavior. Appleton-Century-Crofts.
Sundberg, M. L. (2008). Verbal behavior milestones assessment and placement program: VB-MAPP. AVB.
Sundberg, M. L. (2016). Verbal stimulus control and the intraverbal relation. The Analysis of
Verbal Behavior, 32(2), 107–124. https://doi.org/10.1007/s40616-016-0065-3
Williams, K. T. (2019). Expressive Vocabulary Test (3rd ed.) NCS Pearson.